
The Capital One Hackathon, Part I
This past weekend, I participated in a hackathon sponsored by Capital One with my co-workers Yuan Chen and Dwipam Katariya. Part of the reason I signed up was because they were giving away $50,000 in cash to the top three teams. Another reason, perhaps more important because I had no expectation of winning, was learning how to work together effectively under pressure, as that would be important when the work together at the company.
For your reference, the EventBrite link to the hackathon can be found here.
The overarching goal for the teams competing was to come up with a solution to better service day-to-day finances for families. For preparation, the hackathon people put out two webinars on what data was available, and how to win at a hackathon. They gave us two million transactions for 2500 accounts, in a JSON format meant to be loaded into mongoDB. We settled on creating a machine learning solution that trained on the mongoDB data, to be presented in a user-friendly dashboard with the classifier and raw data loaded in through an API.
The hackathon itself was well appointed, very different than the university hackathons that I attended in college. We were based out of the National Union Building; there was Secret Service next door for an event at the Marriott because important people were probably there. We got actual food instead of just pizza. Turns out, if you're an actual company and you need to come up with some game-changing ideas or get self-motivated hires or what have you, a hackathon counts as a relatively cheap affair.
In the end, we were able to come up with an API, and both a V1 and V2 frontend. I did most of the work, because as it turned out, the data was fake and random. There were 17-year-olds who spent $4000 per month, and Panda Express transactions that were $300. It's okay; at the office, Yuan and Dwipam do all the important work, and I do everything else.
The API can be found live here. I
used primarily Flask, flask_restful, and PyMongo, and designed the API to be
as stateless as possible. As it turns out, it's difficult to have a completely
stateless backend if you are using NoSQL. REST endpoints in particular don't map
nicely to documents, and some finagling needs to take place in order for you to
not return the whole document. Either that or I'm not using the right queries;
right now I'm only using find($QUERY).
You can make the following calls to the API using curl:
# Hello world
curl -X GET https://api-capital-one-yingw787-1.herokuapp.com
# GET on /v1/account/<account_id> with account ID 100100000 (IDs increment the latter 1, so next account ID in order would be 100200000)
curl -X GET https://api-capital-one-yingw787-1.herokuapp.com/v1/account/100100000
# GET on /v1/customer/<customer_id> with customer ID 100110000
curl -X GET https://api-capital-one-yingw787-1.herokuapp.com/v1/customer/100110000
# GET on /v1/transaction/<transaction_id> with transaction ID 1002200003
curl -X GET http://api-capital-one-yingw787-1.herokuapp.com/v1/transaction/100220003
# GET on /v1/payments/<account_id> with account ID 100100000
curl -X GET https://api-capital-one-yingw787-1.herokuapp.com/v1/payments/100100000
# GET on /v1/rewards/<account_id> with account ID 100100000
curl -X GET https://api-capital-one-yingw787-1.herokuapp.com/v1/rewards/100100000
# GET on /v1/total_rewards_remaining/<account_id> with account ID 100100000
curl -X GET https://api-capital-one-yingw787-1.herokuapp.com/v1/total_rewards_remaining/100100000
These endpoints map exactly to the data as it is laid out in the database. So,
customer is a field within account, which is the top-level document.
customer is an indexed list, with each customer having a transaction, which
is also an indexed list. Because they're indexed as such, they get their own
top-level API.
According to a coworker, endpoints that allow you to GET multiple objects by searching another index (say, getting all customers that share the same account ID) is also RESTful, so I built out those endpoints as well:
# GET all transactions by customer
curl -X https://api-capital-one-yingw787-1.herokuapp.com/v1/transaction/customer/100110000
# GET all transactions by account
curl -X http://api-capital-one-yingw787-1.herokuapp.com/v1/transaction/account/100100000
# GET all customers by account
curl -X http://api-capital-one-yingw787-1.herokuapp.com/v1/customer/account/100100000
It's a little different in production than it is in development, even in Heroku.
Since I'm building out my front-ends on different servers and did not have time
to add in validation at all, I decided to add in flask_cors and do CORS(app)
in order to turn off all validation server-side. Also, since I'm using HTTPS in
my frontend (apparently) and my API was not, I needed to add in flask_sslify
in order to add in SSL.
The mongoDB on local ended up being "huge", with about 600MB of data. That would mean I would need to pay for Heroku, which I am not willing to do, so I just took the first 50 documents and put them into the production data. Try and see how many endpoints you can hit!
Just to prove I'm not lying and it actually worked:
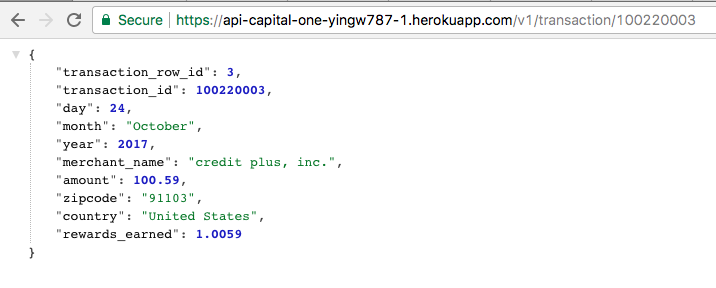{kind=link}
{kind=link}
The first front-end can be found live
here. It's built primarily
using create-react-app. There's a fake auth panel that actually appends the
account ID and customer ID (defaulted to the first ones) to a query string,
which is pulled off the next page and sent to the backend through axios and
delivered as a promise. I used promises because I'm familiar with them and
because updating state with promises is really easy in React (once you get the
hang of it). I followed this folder
structure
in order to scale my project. The big thing here was that I forgot Bootstrap.
Very big deal in a hackathon. Hey, I hadn't written any front-end code for a few
months, I'm a bit rusty.
It doesn't do much, pretty much just confirms that my API is hittable. I was like "I need something better than this to show at demo time". So I went ahead and tried to build out another front-end, because thin clients are cheap and you should throw one away (especially if it's crap).
{kind=link}
{kind=link}
{kind=link}
Use Bootstrap. Please.
There's this company called Creative Tim that gives away free UI templates. There's this dashboard template I found on there that was pretty good, so I decided to download it and boot it up. It worked like a charm. Then I ripped out everything that was irrelevant and pasted in some hardcoded data. Because it's a hackathon. This was the result:
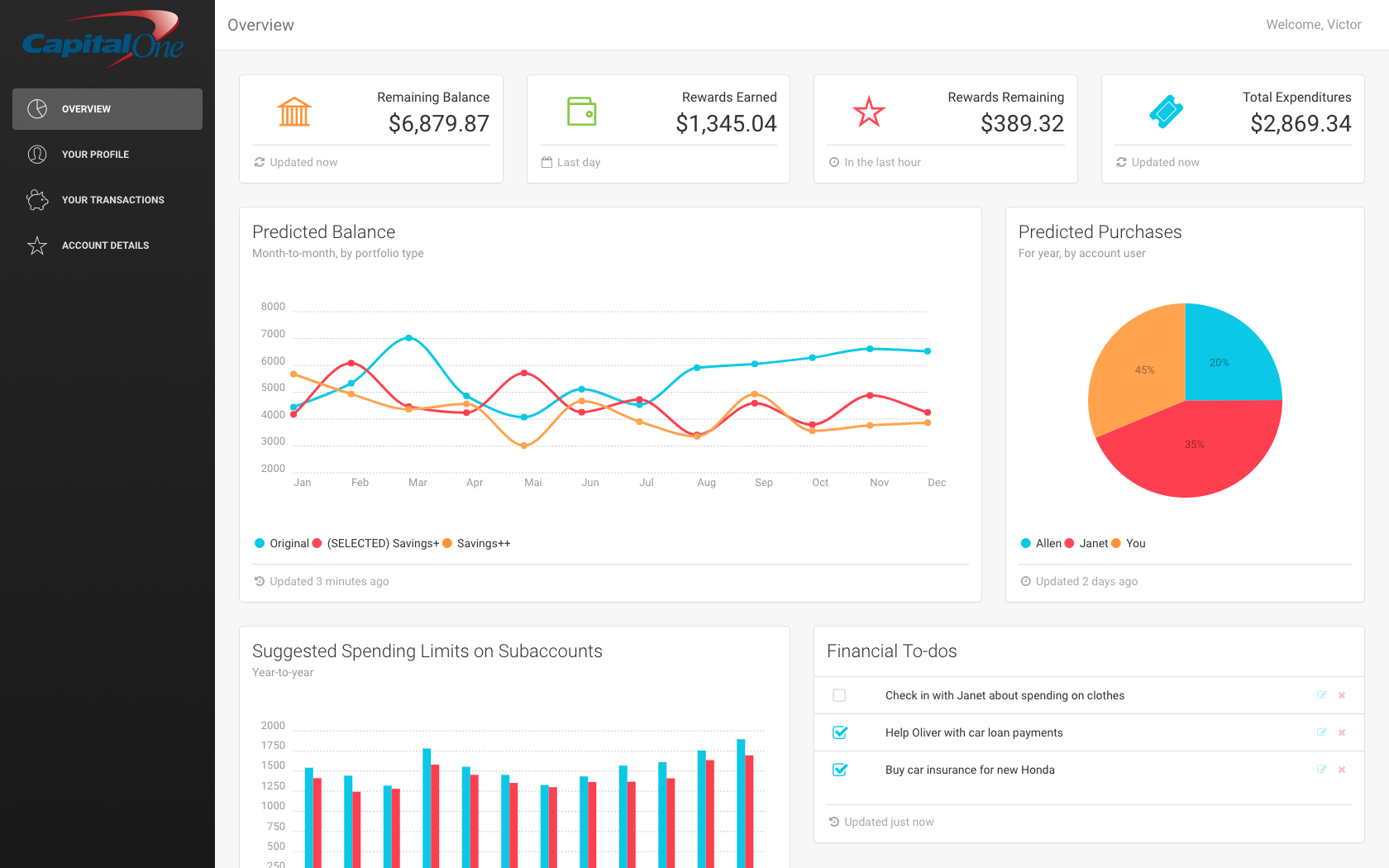{kind=link}
The dashboard was really the key. This displayed our "predicted" results, where we fictitiously generated a budget portfolio from your transaction history. We also generated spending limits for account holders, and what expenses each account holder would have as a percentage of the total account.
The remaining functionality should already exist as part of Capital One:
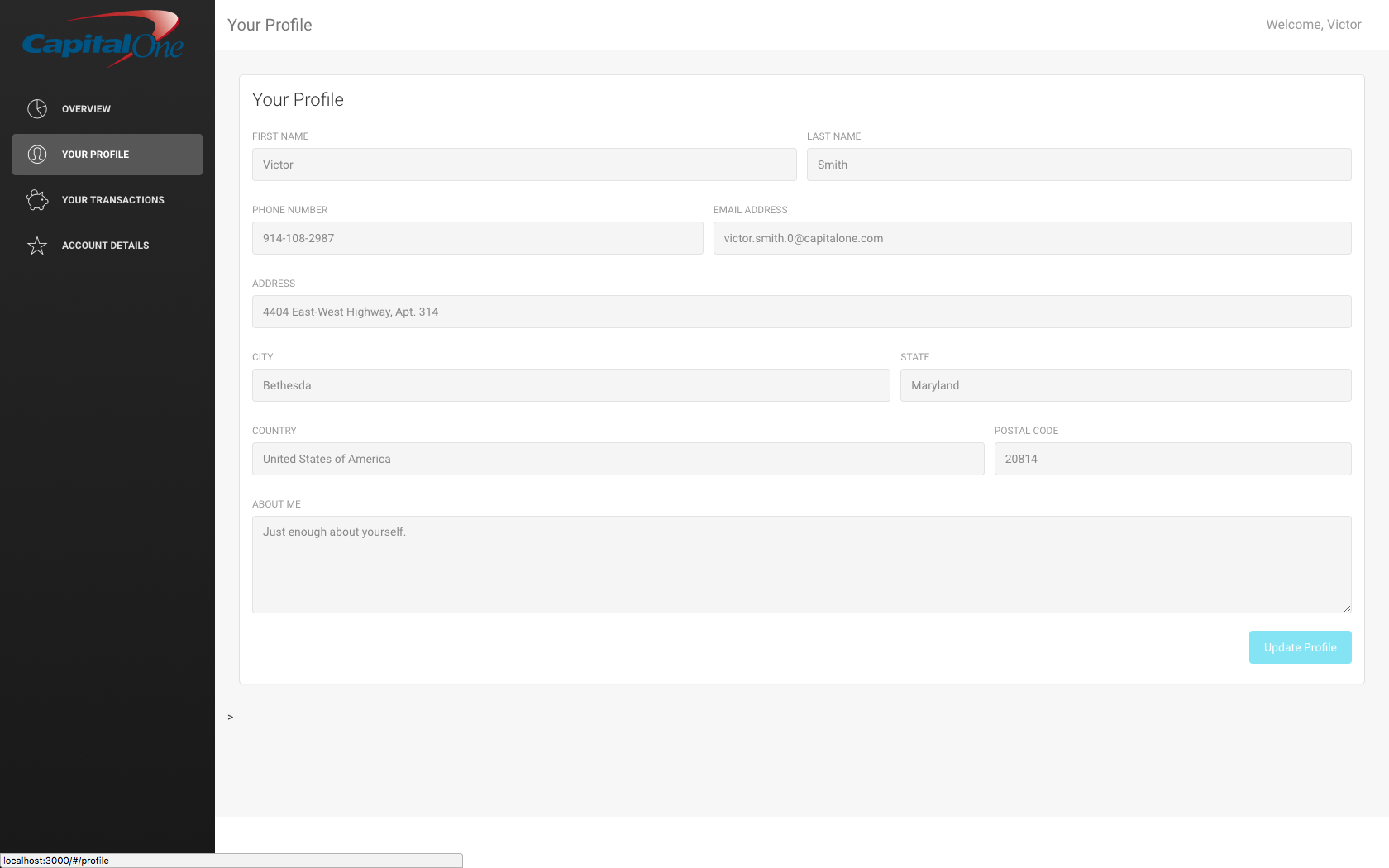{kind=link}
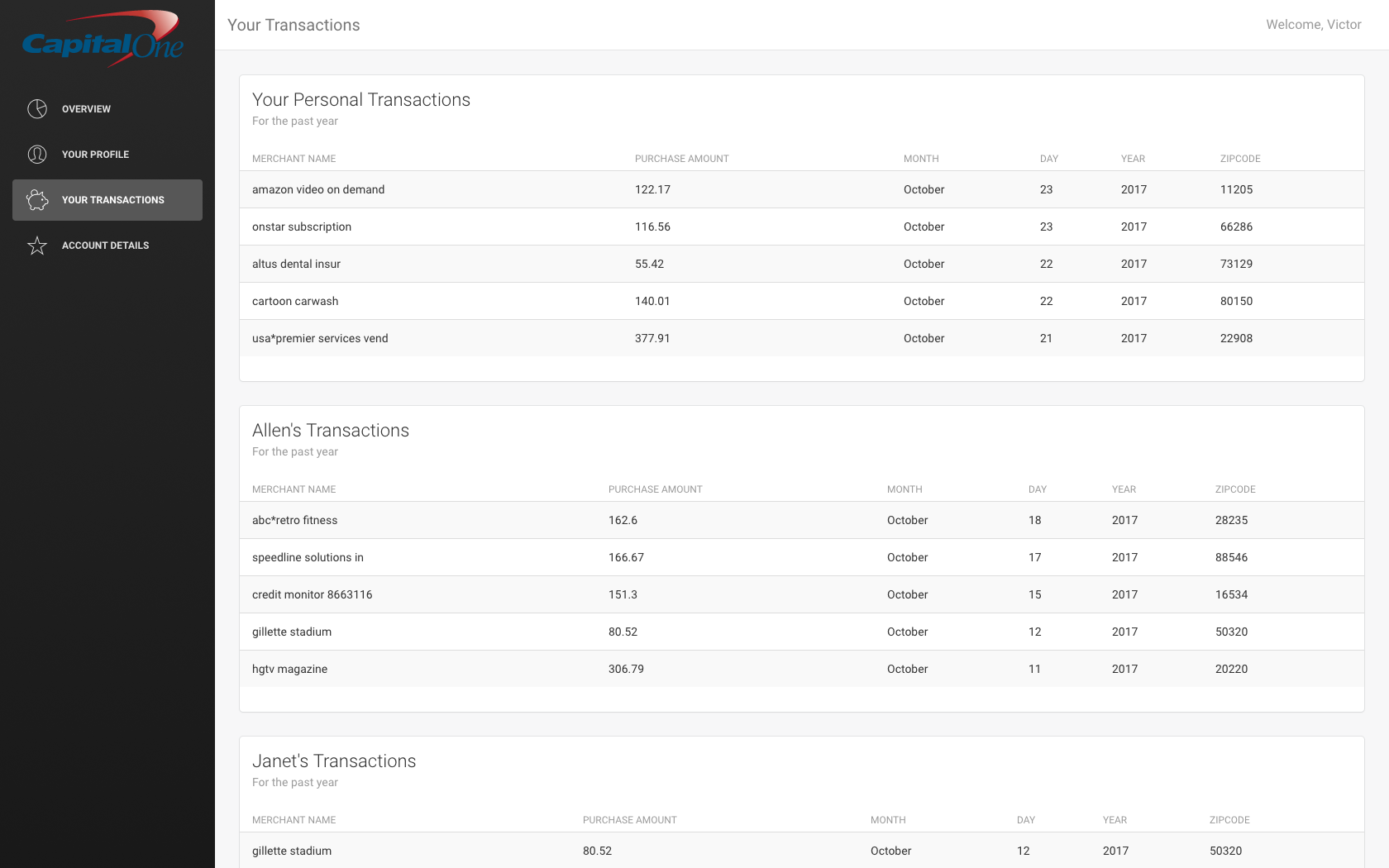{kind=link}
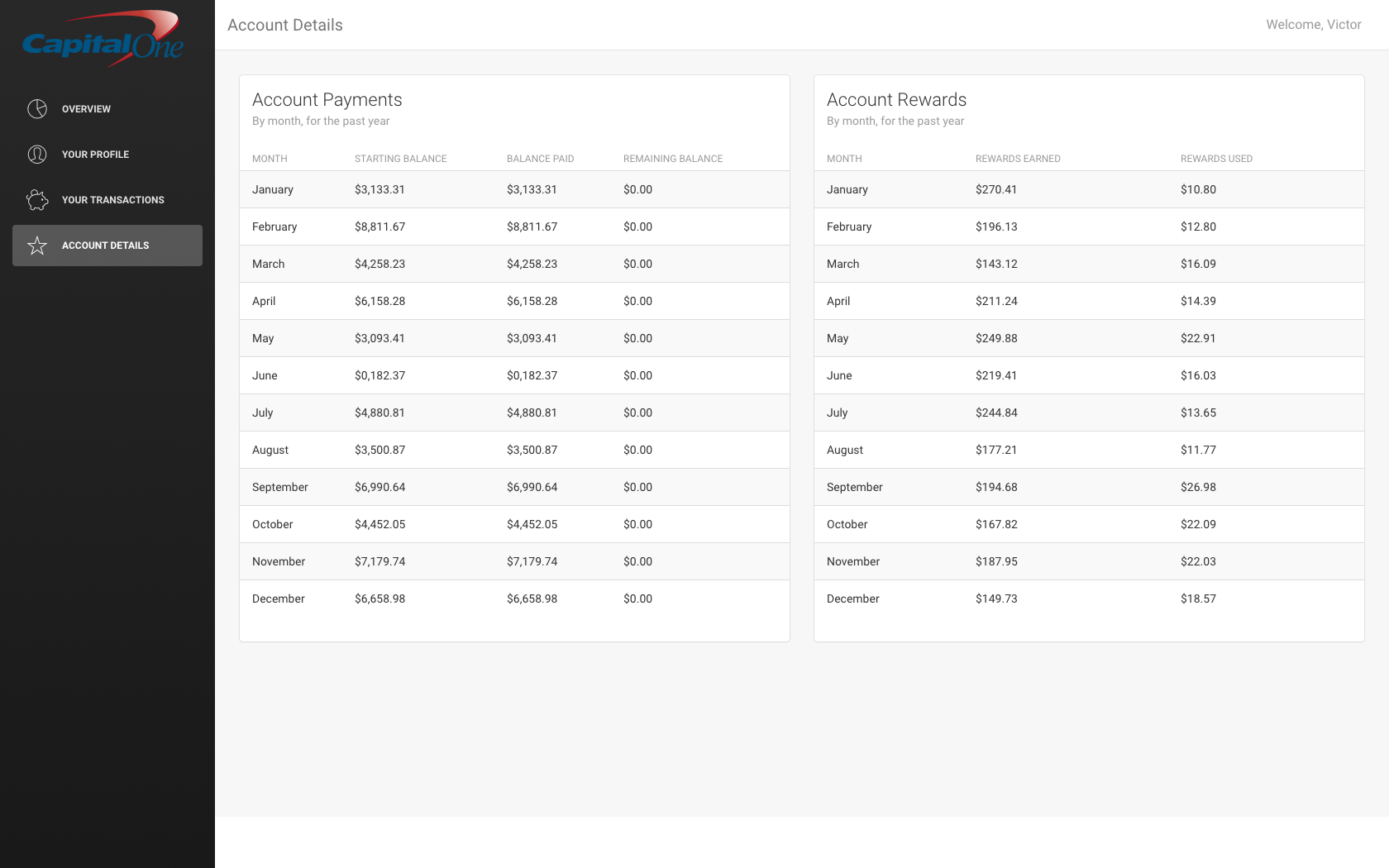{kind=link}
as a bonus, it's also mobile-friendly:
{kind=link}
This site is live here.
This post would not be complete without some open source repositories, so here you go:
V1 API: https://gitlab.com/yingw787/capital-one-hackathon-backend-2
V1 APP: https://gitlab.com/yingw787/capital-one-hackathon-frontend-1
V2 APP: https://gitlab.com/yingw787/capital-one-hackathon-frontend-2
So, there you have it. I'll write up a post-mortem and debriefing we did as a team in a separate post.